Horizontal vs. Vertical Scaling: Architectural Dissection & Best Practices
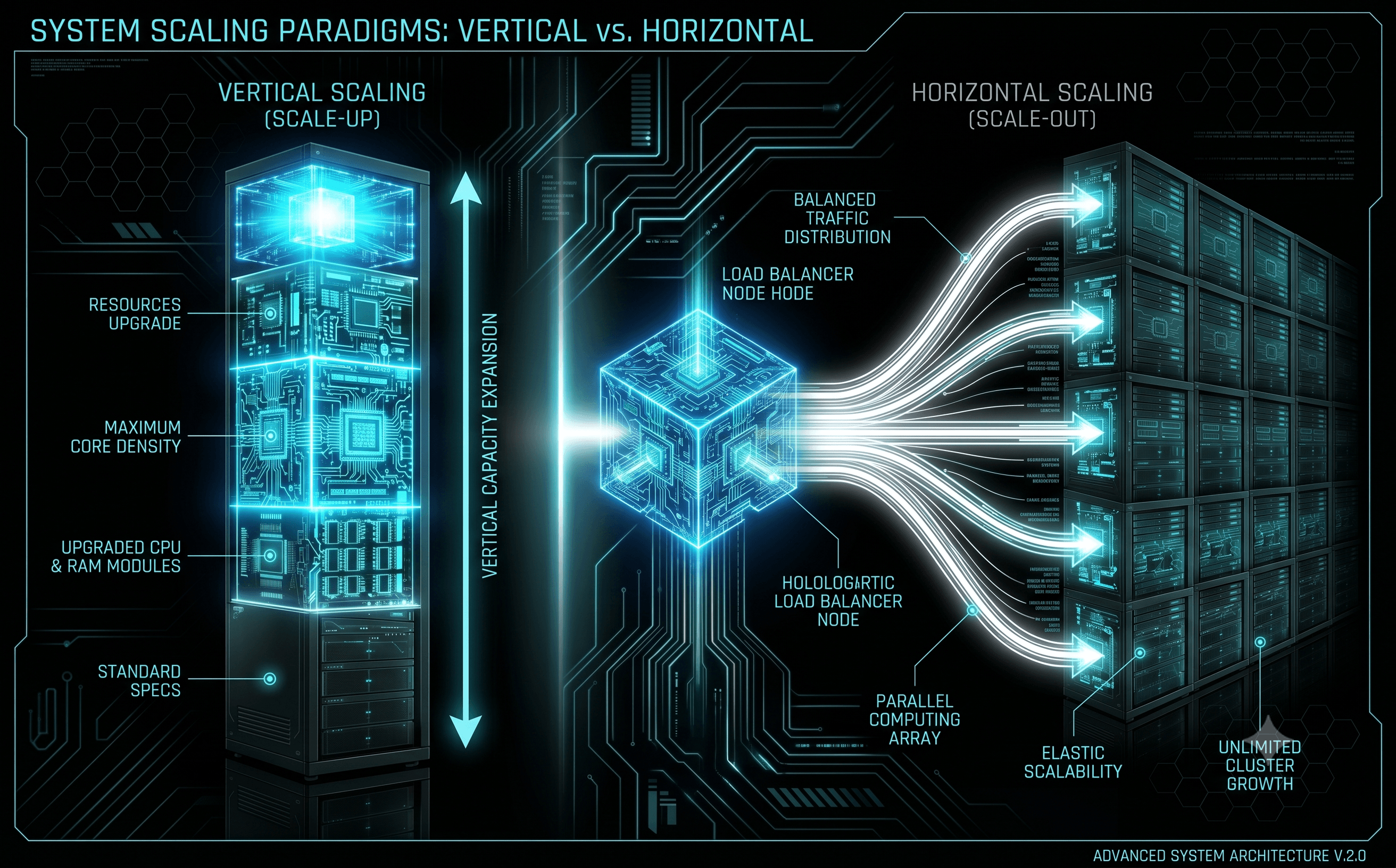
In system design, scalability is the ultimate architectural North Star. It defines an infrastructure’s capacity to handle an increasing volume of concurrent requests without sacrificing performance metrics like latency or throughput. When traffic spikes, systems inevitably collide with hardware or software constraints.
Resolving these bottlenecks boils down to two fundamental scaling vectors: Vertical Scaling (Scale-Up) and Horizontal Scaling (Scale-Out). To construct production-ready ecosystems, engineers must look past textbook summaries and dissect the deep mechanical trade-offs, state problems, and infrastructure best practices hidden behind both approaches.
1. Vertical Scaling (Scale-Up): Maximizing Bare-Metal Power
Vertical scaling is the process of increasing the computational power of a single existing node within your infrastructure. Put simply, you take an active server instance and upgrade its underlying hardware components—replacing a CPU with more cores, expanding RAM capacity, or swapping older storage setups for ultra-fast NVMe SSDs.
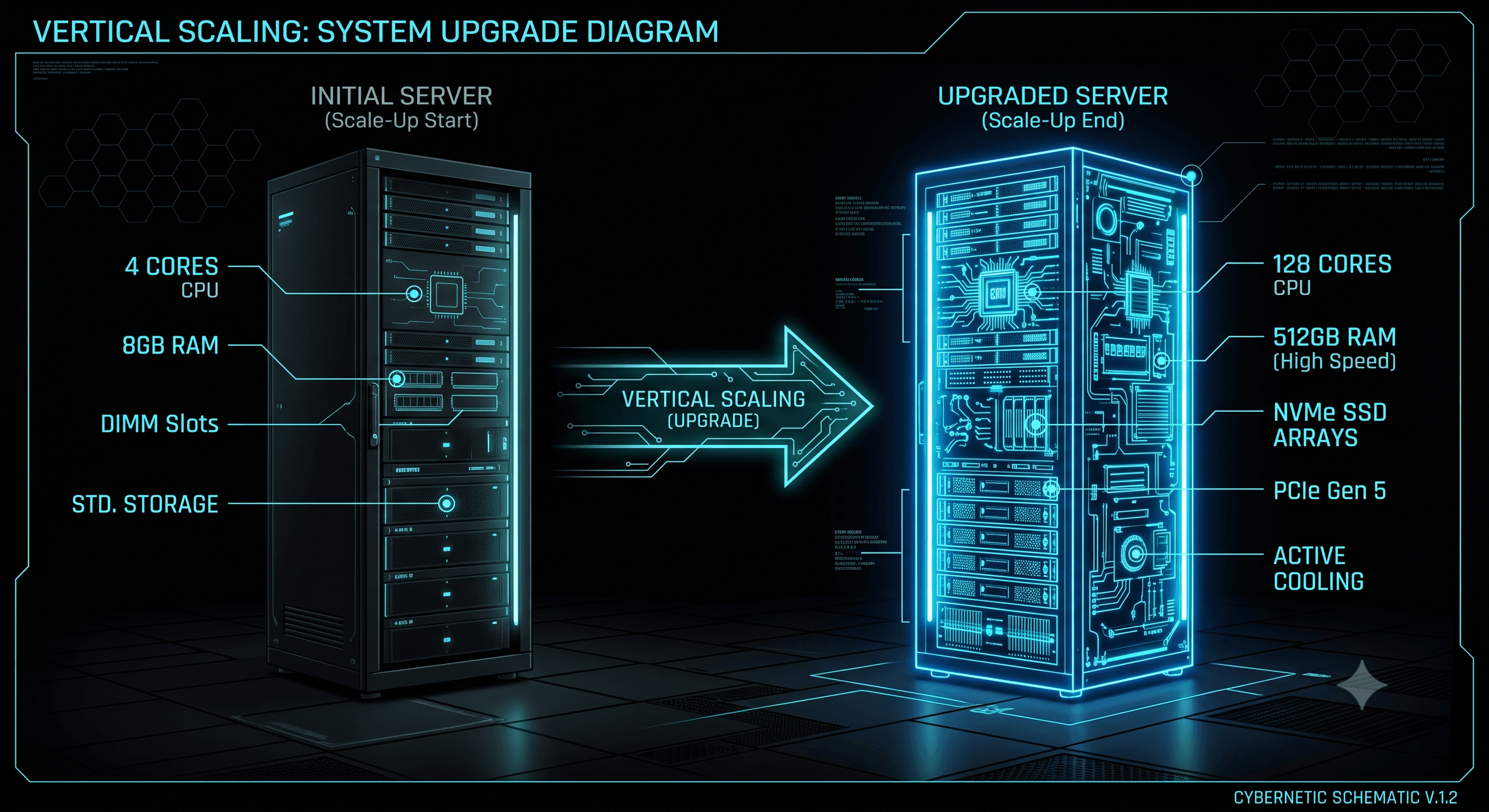
Mechanics and Execution
From a structural deployment standpoint, Scale-Up is exceptionally straightforward. Your core codebase remains entirely untouched. Your application logic doesn't need to account for complex distributed networks, cross-node data synchronization, or network hop latencies. The runtime environment simply gains access to a broader, monolithic resource pool to execute resource-heavy execution logs and concurrent threads within a single operating system kernel.
Critical Engineering Bottlenecks
- The Hardware Ceiling: You cannot add resources indefinitely. Every server motherboard, whether a custom bare-metal rack or an enterprise instance on AWS or Google Cloud, has a hard physical limitation on the maximum number of CPU cores and RAM slots it can accept. Once you hit that threshold, vertical scaling reaches its terminal velocity.
- Single Point of Failure (SPOF): Running a monolithic setup leaves your application highly vulnerable. If that single, highly powerful server suffers a kernel panic, power supply failure, or hardware degradation, your entire platform drops offline instantly. There is no built-in high availability.
- Deployment Downtime: Upgrading hardware on a single node typically requires a system reboot or instance termination. Stopping the server to provision extra resources results in a hard interruption of service, which can damage commercial capture profiles.
2. Horizontal Scaling (Scale-Out): Distributed Parallel Architecture
Horizontal scaling drops the reliance on a single supercomputer. Instead, it scales out the system's capacity by adding more server nodes into your infrastructure pool. You construct a distributed, resilient cluster out of multiple standard, moderately provisioned computing machines (often referred to as commodity hardware).
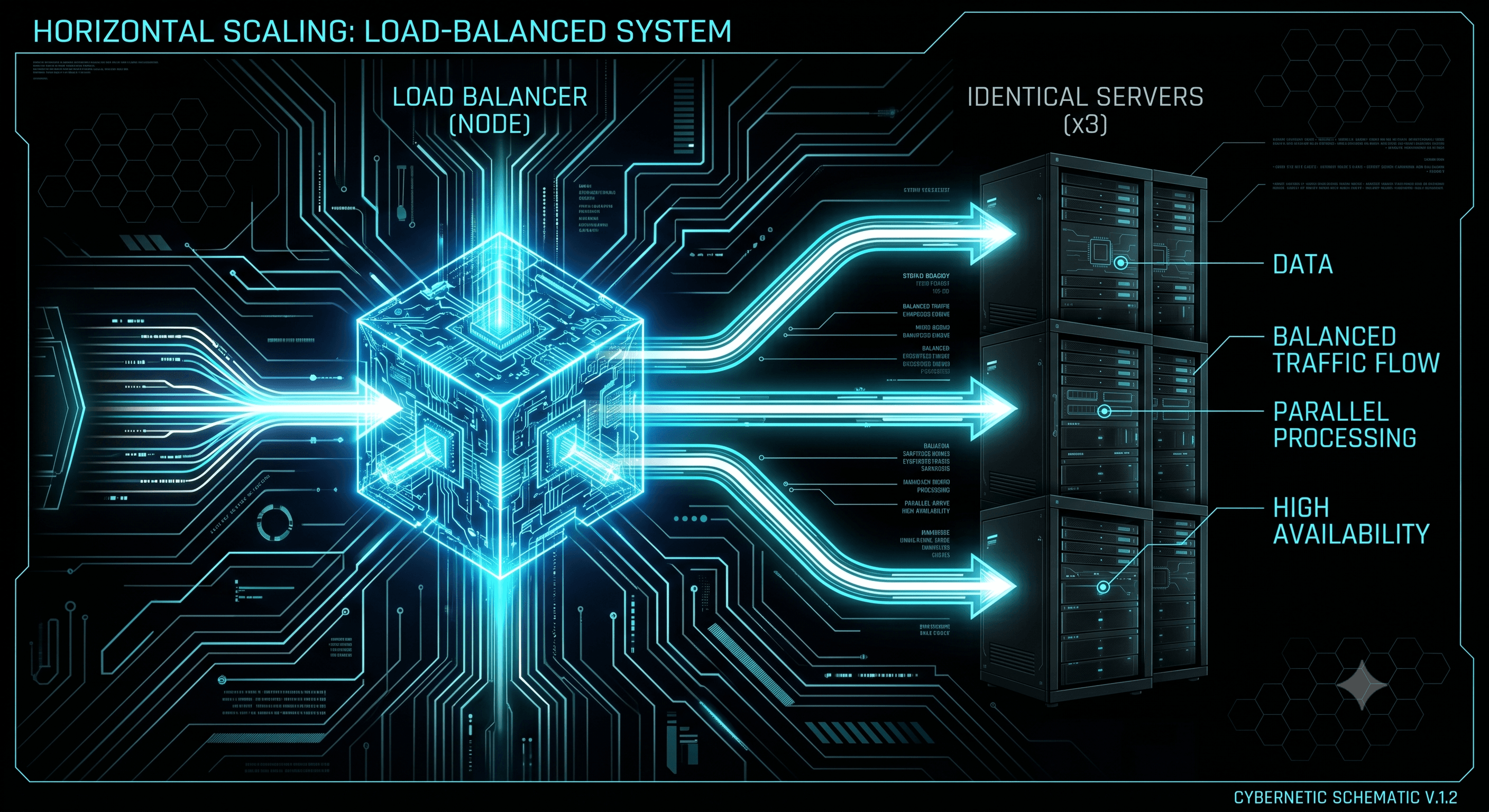
Mechanics and Execution
Scale-Out requires the introduction of an entirely new network abstraction layer: the Load Balancer. Technologies like Nginx, HAProxy, or an AWS Application Load Balancer (ALB) act as the single entry point for all incoming traffic. The Load Balancer accepts client HTTP/TCP requests and uses algorithms like Round Robin, Least Connections, or IP Hashing to systematically route the load across your parallel pool of application servers.
Architectural Advantages
- Infinite Elasticity Profiles: Horizontal scaling completely breaks past the physical limitations of a single machine. If your user base multiplies ten times over, you don't hunt for a bigger processor; you simply spin up ten more virtual nodes to absorb the traffic spike.
- High Availability (HA) Resilience: By distributing execution across independent nodes, you eliminate your Single Point of Failure. If Server Node B crashes due to an unhandled exception or memory leak, the Load Balancer detects the failure via automated Health Checks and invisibly reroutes traffic to nodes A and C. The end-user experiences zero service degradation.
- Dynamic Auto-Scaling: Distributed clusters allow you to write rules that automatically provision new instances during peak operational hours (e.g., when cluster-wide CPU utilization crosses 75%) and terminate idle instances when traffic drops, drastically reducing cloud billing overhead.
3. The Structural Breakdown: Deep Technical Trade-offs
Evaluating whether to scale up or scale out requires a strict analysis of your system's operational constraints.
Architectural Complexity
Vertical scaling keeps system design minimal. Since everything runs locally, debugging memory heaps and tracking execution flows is simple. Horizontal scaling introduces massive complexity. Your engineering team must design completely state-free architectures, manage distributed logging systems, and handle complex container orchestration layers like Docker and Kubernetes.
Network Latency
Monolithic Scale-Up environments boast near-zero communication latency. Threads and components pass data instantly via local Inter-Process Communication (IPC) or shared system memory. Scale-Out environments must communicate over a network grid. Nodes utilize APIs, RPC protocols, or gRPC streams to sync states, adding inevitable network transit times to the overall request cycle.
Cost Trajectory
Upgrading to a single ultra-powerful machine scales costs non-linearly. High-end, enterprise-grade processors and high-capacity RAM modules carry massive premium price tags. Conversely, horizontal scaling expands using standard, highly optimized cloud instances. Adding cheap, commodity nodes scales your resource costs in a linear, predictable fashion.
4. The Database State Problem: Navigating the CAP Theorem
While scaling a stateless application tier (like a Next.js API or microservice) horizontally is highly efficient, scaling the stateful data storage tier (like a PostgreSQL or MySQL database) introduces significant data-integrity challenges.
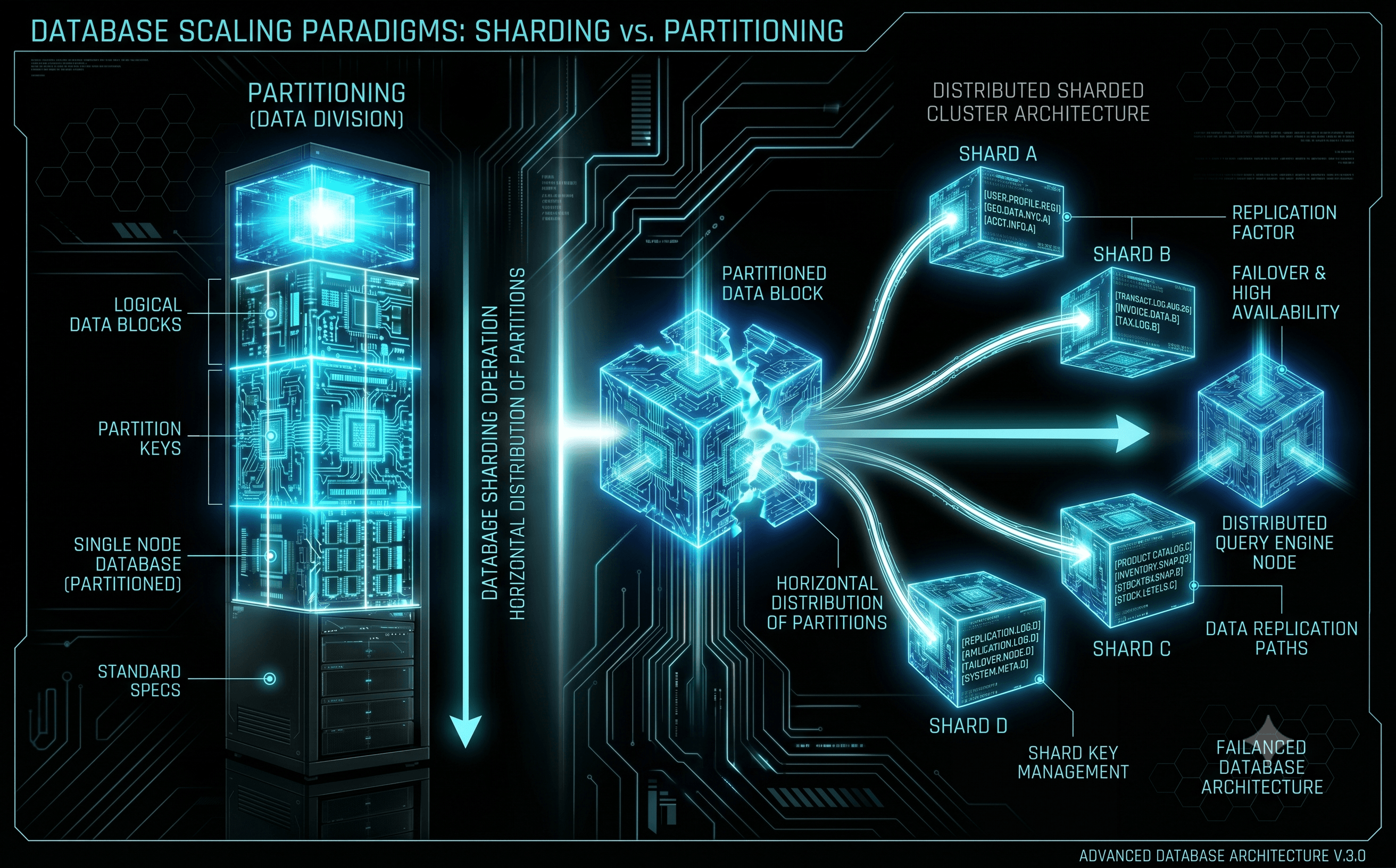
Distributed database scaling is governed by the CAP Theorem, which states that a distributed data store can simultaneously provide only two out of three core guarantees: Consistency (every read receives the most recent write), Availability (every request receives a non-error response), and Partition Tolerance (the system continues to operate despite network drops).
To scale storage engines horizontally without breaking transaction integrity, you must implement specialized patterns:
- Read Replicas (CQRS Concept): You maintain a single Primary database node dedicated exclusively to data writes, which then replicates data asynchronously to multiple read-only Slave replicas. This is perfect for systems with heavy read ratios, like content portals or web logs.
- Database Sharding: This involves breaking a massive database table apart horizontally across entirely separate physical database servers based on a distinct Shard Key (e.g., partitioning users by unique Customer ID blocks or geographic zones). While highly performant, sharding introduces immense query routing complexity and restricts your ability to perform cross-shard SQL JOIN operations.
5. Decision Matrix: Best Practices for Production Deployment
When to Execute a Vertical Scale-Up Strategy
- Minimum Viable Product (MVP) Launches: When testing a product market fit, engineering speed is your primary asset. Scaling vertically on a single server allows you to focus on shipping features without sinking hours into building complex distributed deployment pipelines.
- Complex Relational Databases: Databases that rely heavily on deep ACID compliance, immediate data consistency, and heavy multi-table JOIN operations run best on scaled-up, high-performance bare metal with ample RAM.
- Ultra-Low Latency Pipelines: If your system cannot tolerate the millisecond delays introduced by distributed data transport over internal private networks, a single hyper-optimized node is the correct choice.
When to Execute a Horizontal Scale-Out Strategy
- Stateless Web Applications: High-concurrency runtime tiers, public API endpoints, and web frontend architectures should be packaged into containerized environments built for automated horizontal scaling from day one.
- Volatile Traffic Conditions: E-commerce systems, media streaming platforms, and SaaS products that experience sudden, massive traffic spikes must deploy horizontal auto-scaling matrices to protect systems from crashing.
- Mission-Critical High-Availability Environments: If your business logic associates every single second of downtime with severe commercial loss, your architecture must be decoupled, distributed, and spread horizontally across multiple distinct cloud availability zones.
Conclusion
Modern, enterprise-grade cloud architecture rarely relies on an absolute choice between these two vectors. Instead, the gold standard is a hybrid engineering strategy. You provision your servers with a highly practical, cost-efficient layer of vertical hardware power (Scale-Up) to establish a strong performance baseline per instance, but you package those nodes into an elastic, horizontally distributed cluster (Scale-Out). This combined approach delivers perfect infrastructure elasticity, keeps cloud overhead linear, and guarantees that your technical ecosystem will survive massive commercial scale.
Optimize your architecture around hard data metrics, audit your data consistency needs, and respect the network trade-offs. How are you structuring the scaling vectors in your current system designs? Drop your implementation notes below.